一、决策树的描述
决策树(decision tree)
一种监督学习方法
优点
- 速度快
- 易于理解、可解释性强
- 需要样本量小
任务类型
- 分类
- 回归
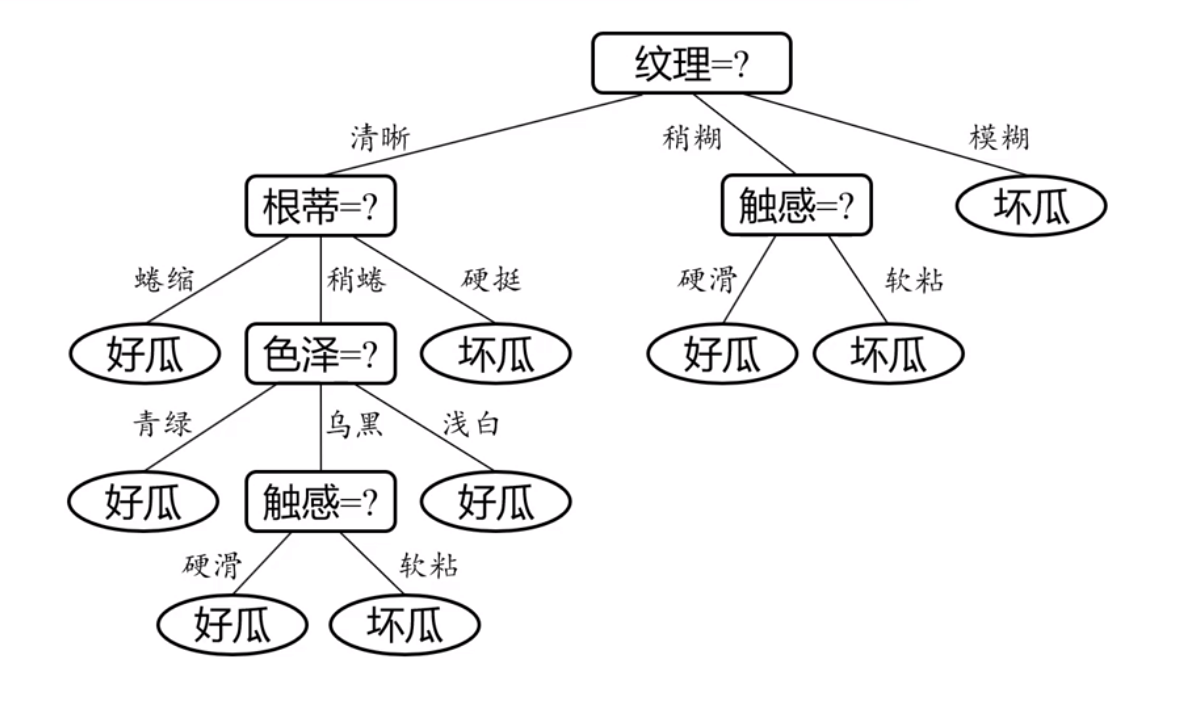
决策树一般分三步,
(1)特征选择
(2)决策树生成
(3)决策树剪枝
1、度量混乱程度——信息熵
“信息熵”是度量样本级和纯度最常用的一种指标。热力学里有一个熵的概念,熵就是来形容系统混乱程度的,系统越混乱,熵就越大。信息熵也具有同样的意义,不过它描述的是随机变量的不确定性(也就是混乱程度)。
假定当前样本集合D中第K类样本所占的比例记作:$p_k(k=1,2,…,|y|)$
则它的信息熵计算公式为:
$H(D)=-\sum\limits_{i=0}^{|y|}p_klogp_k$
因而可计算出例子中的信息熵:
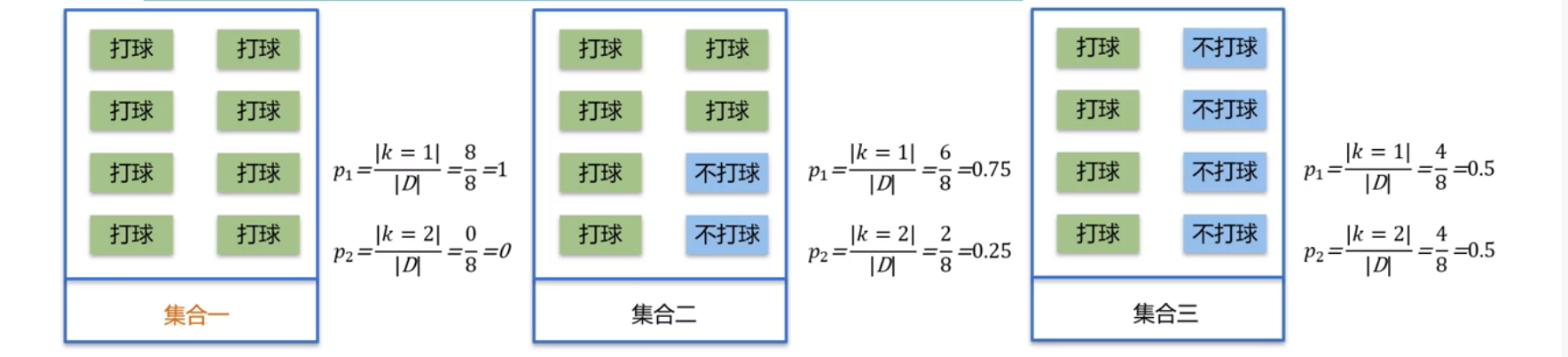

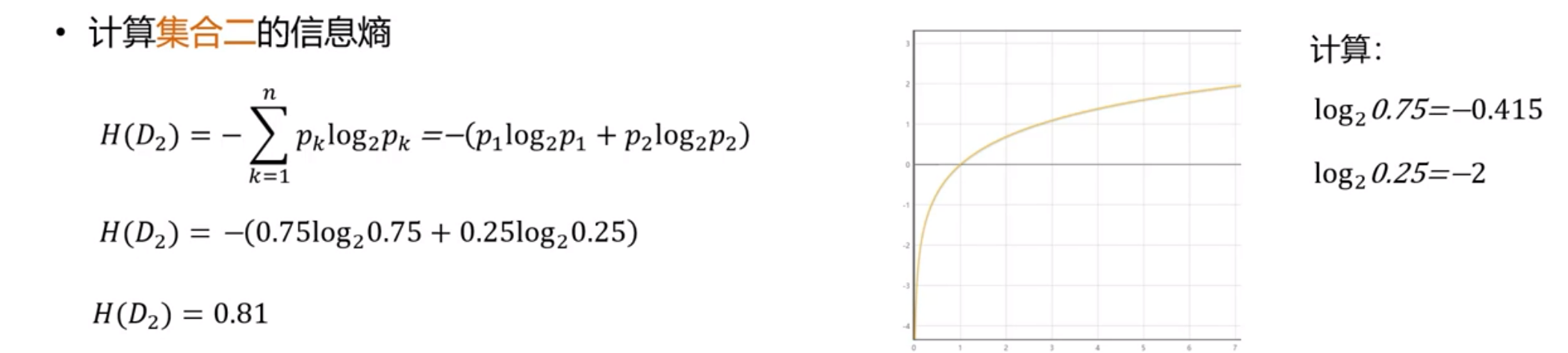
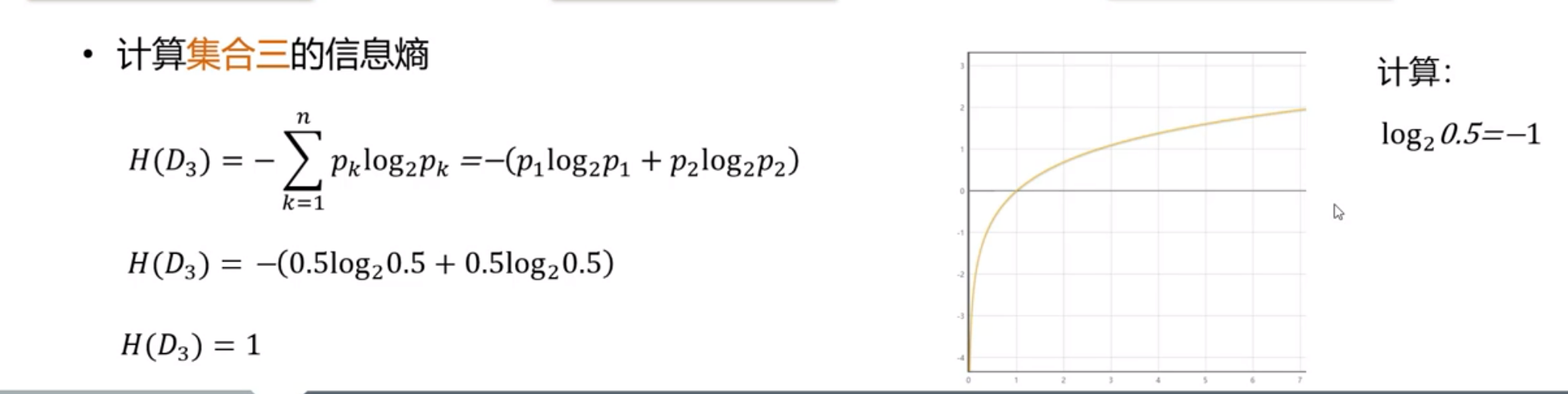
从上面的计算结果中可以看出,信息熵越大,纯度越低。当集合中所有样本均匀混合时,信息熵越大,纯度越低。
信息熵计算练习: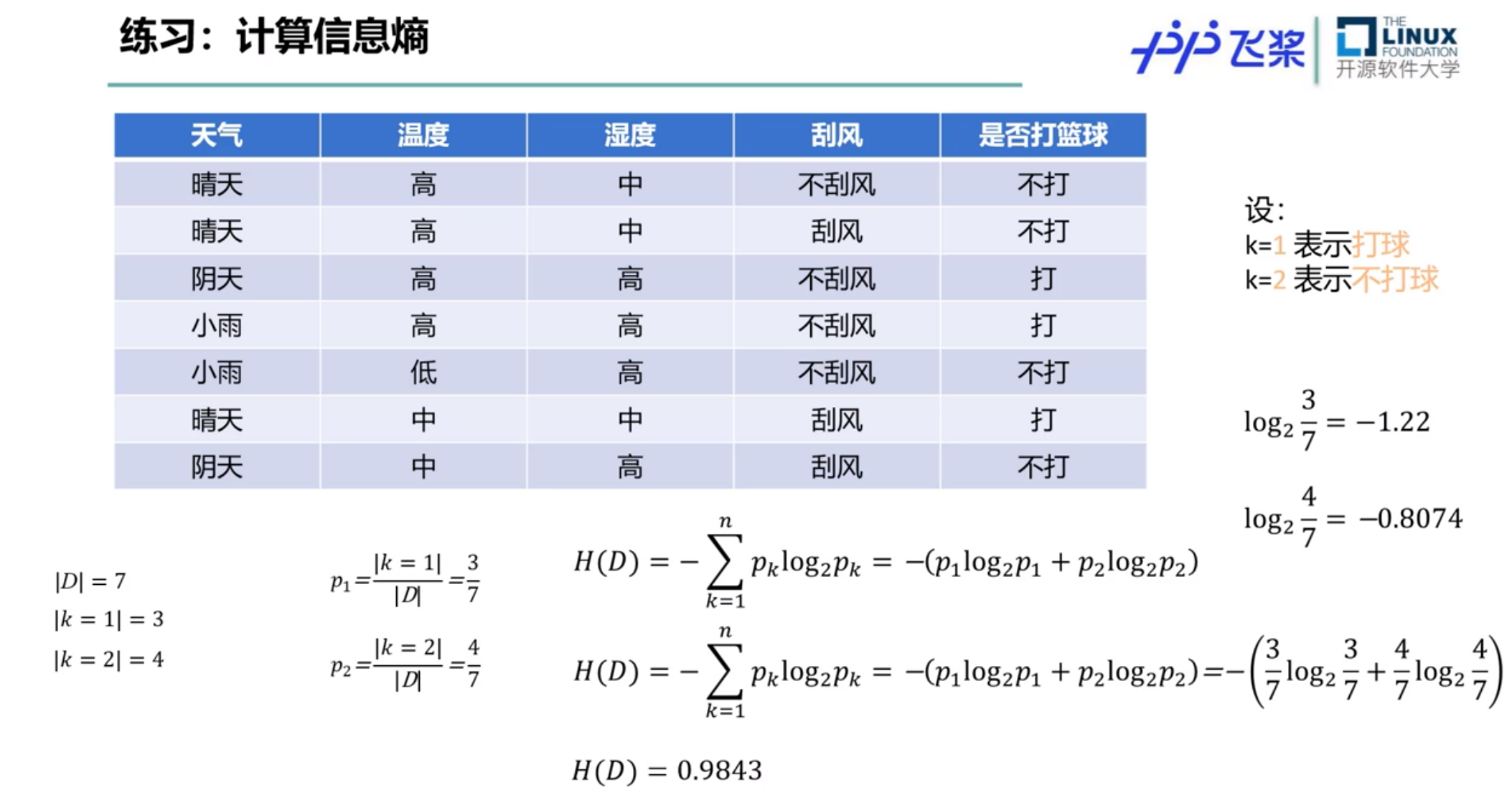
2、信息增益
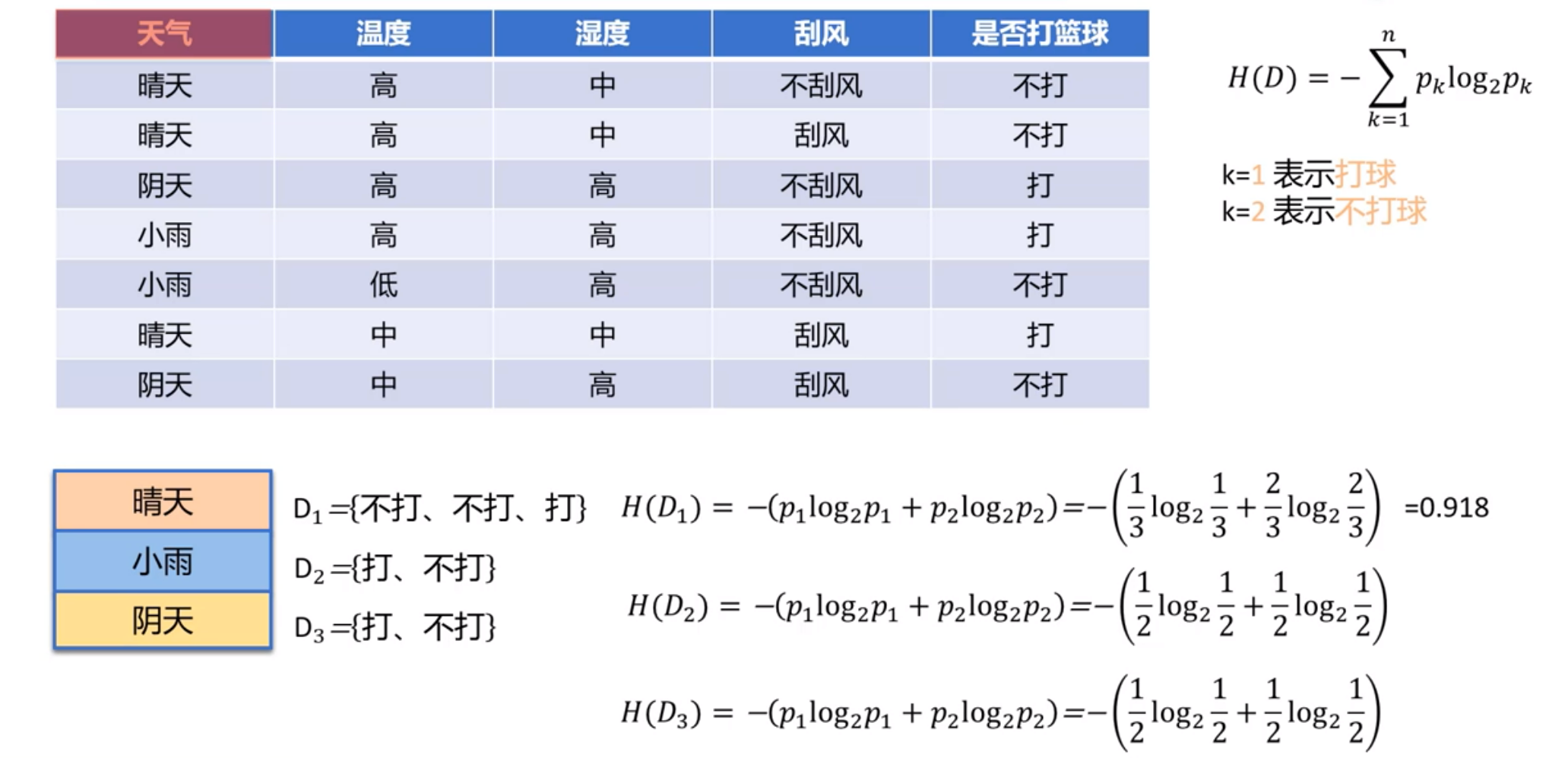
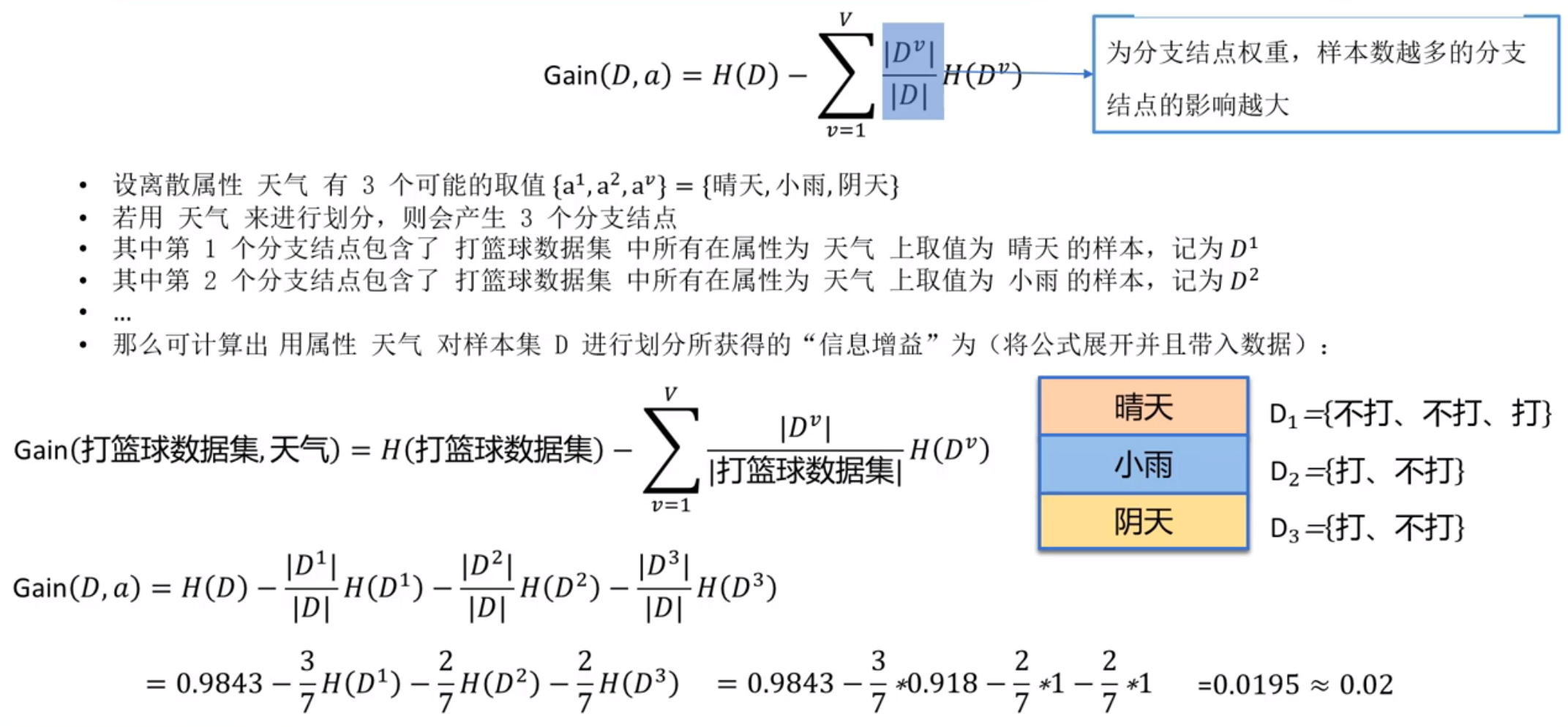
设离散属性a有V个可能的取值{$a^1$,$a^2$,…,$a^v$}
若用a来进行划分,则会产生V个分支节点
其中第v个分支节点包含了D中所有在属性a上取值为$a^v$的样本,记为$D^v$
那么可计算出属性a对样本集D进行划分所获得的“信息增益”为:
其中,$\frac{|D^v|}{|D|}H(D^v)$也被称为条件熵
二、构建决策树
ID3决策树算法使用信息增益来构建决策树,对于所有的属性我们先选择信息增益最大的作为根节点,然后计算其他属性的信息增益再选择最大的作为子节点,一直递归调用该操作,直到信息增益很小或者没有特征为止。
ID3算法的优缺点:
优点:
- 假设空间包含所有的决策树,搜索空间完整
健壮性好,不受噪声影响
- 算法直观、可解释性强。
缺点:
只能处理离散值的属性。
容易产生过拟合的问题
采用了信息增益作为评价标准
信息增益比
信息增益比定义:$Gain_ratio(D,a)=G_r(D,a)=\frac{Gain(D,a)}{IV(a)}$
其中
称为属性a的“固有值”,属性a的可能取值数目越多(即V越大),则$IV(a)$的值通常就越大。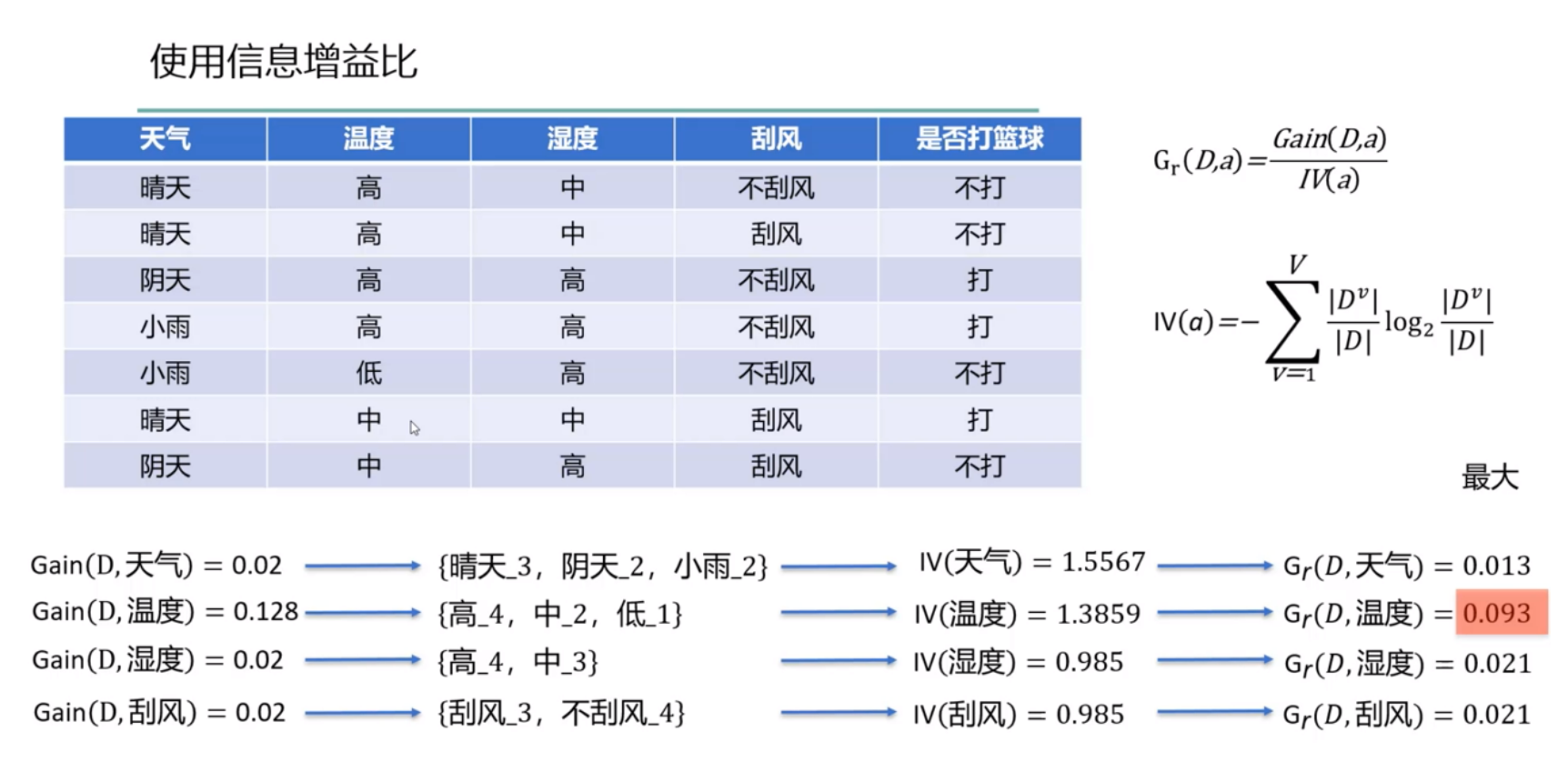
三、离散化、缺失值、剪枝
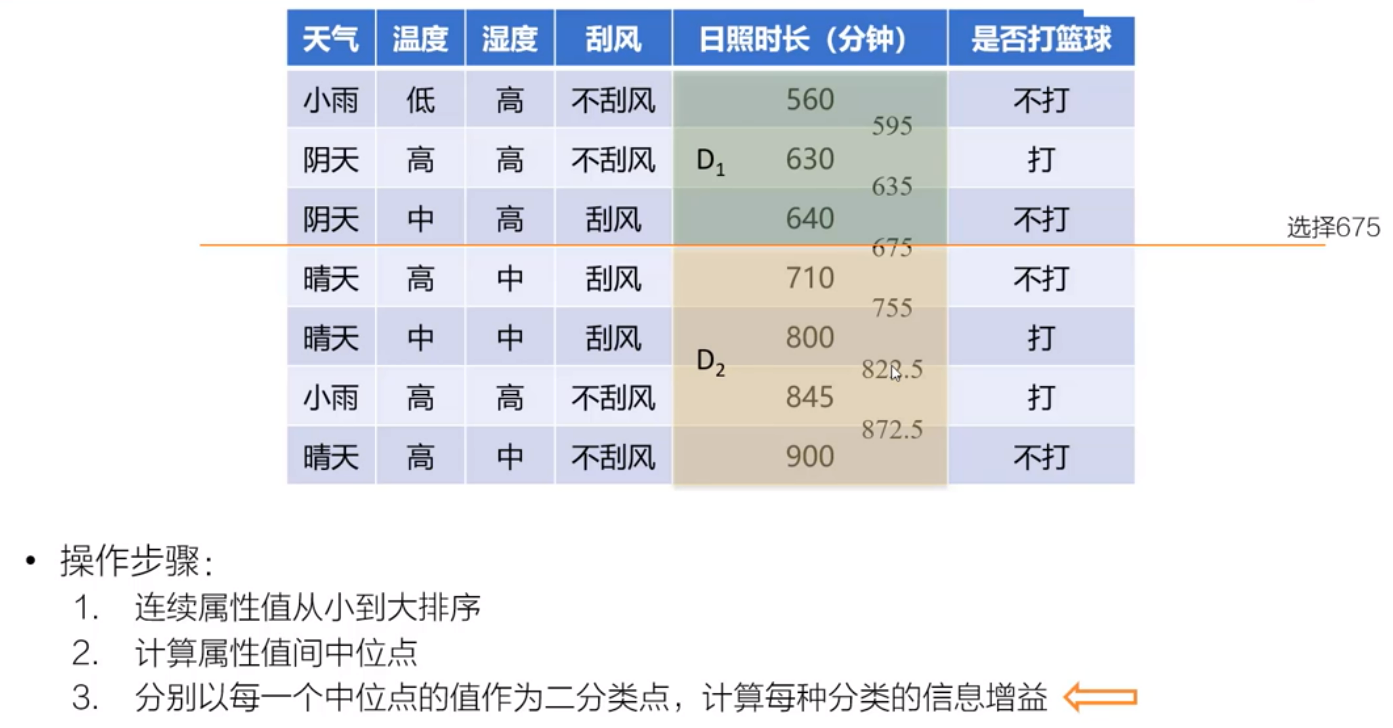
1、连续性属性值的离散化
2、缺失值处理中的问题
不完整样本,即样本的属性值缺失
仅使用无缺失的样本进行学习?
对数据信息极大的浪费
- 使用有缺失值的样本,需要解决哪些问题?
Q1:在训练时,如何在属性值缺失的情况下进行划分属性选择?
Q2:在训练时,给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
Q3:在预测时,若属性值缺失,如何计算?
2.1 缺失值处理
Q1:

若样本$x$在划分属性a上的取值已知,则将$x$划入与其取值对应的子结点,且样本权值在子结点中保持为$w_x$
若样本$x$在划分属性a上的取值未知,则将$x$同时划入所有子结点,且样本权值在与属性值$a_v$对应的子结点中调整为$\widetilde{r_v}\times{w}$(直观来看,相当于让同一个样本以不同概率划入不同的子结点中去)
- 若样本$x$在属性a上的取值已知,则正常按照属性值在决策树上移动
- 若样本$x$在属性a上的取值未知:
- 直接给出分类结果
- 人为赋予最常见的值,然后继续分类过程
3、剪枝策略
- 剪枝的原因:提高泛化能力
- 预剪枝
- 节点内数据样本低于某一阈值
- 所有节点特征都已分裂
- 节点划分前准确率比划分后准确率高
- 后剪枝
- 悲观剪枝方法
- 训练数据集上的错误分类数量来估算未知样本上的错误率
C4.5算法流程图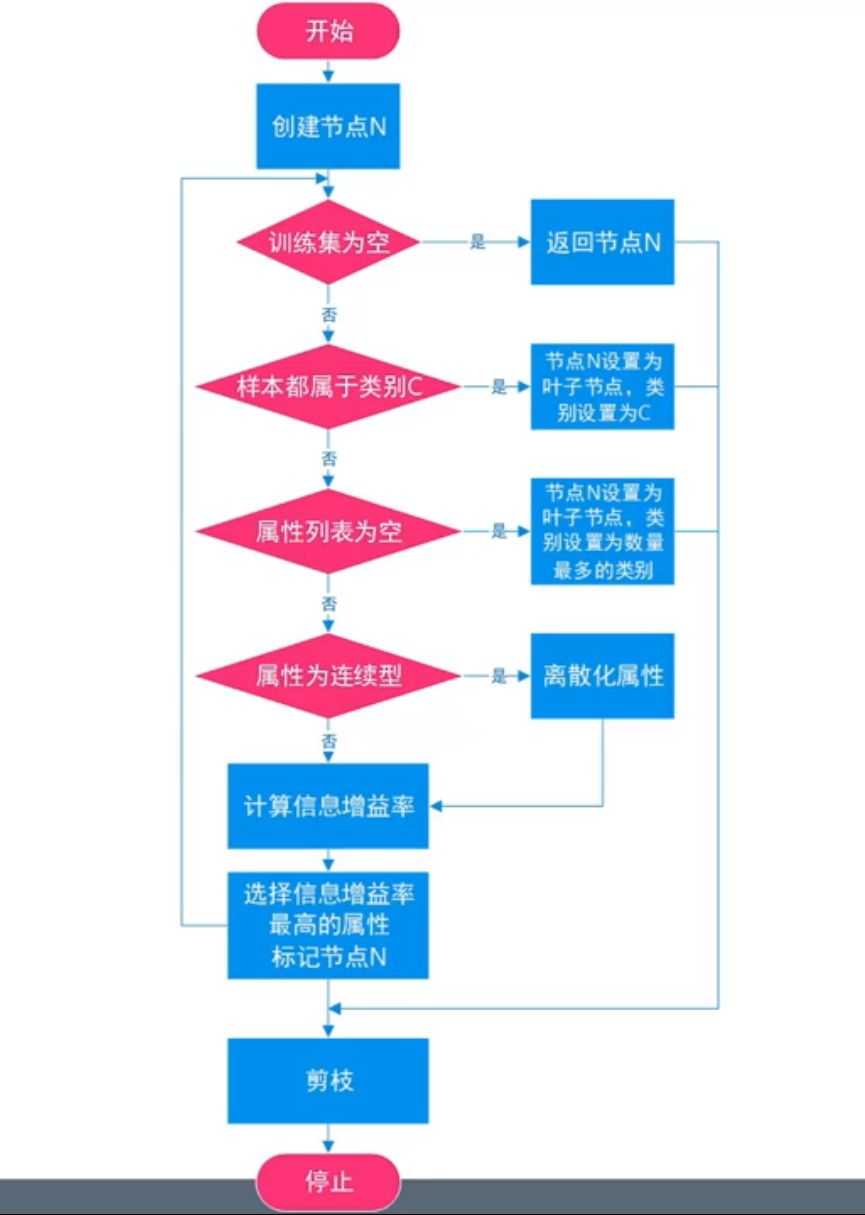
四、决策树的优缺点分析
- 优点
- 可解释性强
- 图形化和直观化
- 需要训练的数据更少
- 可同时用于分类和回归
- 模型复杂度低
- 对缺失值的容忍度较高
- 缺点
- 很容易出现过拟合,对异常值敏感
- 学习能力不强



