支持向量机,SVM的全称是Support Vector Machine
支持向量机算法是一种二分类模型
核心思想:找到空间中的一个能够将所有数据样本划开的超平面,并且使得所有数据到这个超平面的距离最短
一、支持向量机的前导基本概念
- $D_0$和$D_1$是$n$维欧氏空间中的两个点集
- 如果存在$n$维向量$w$和实数$b$
- 使得所有属于$D_0$的点都有$wx_i+b>0$,
- 而对于所有属于$D_1$的点则有$wx_j+b<0$,
- 则称$D_0$和$D_1$线性可分
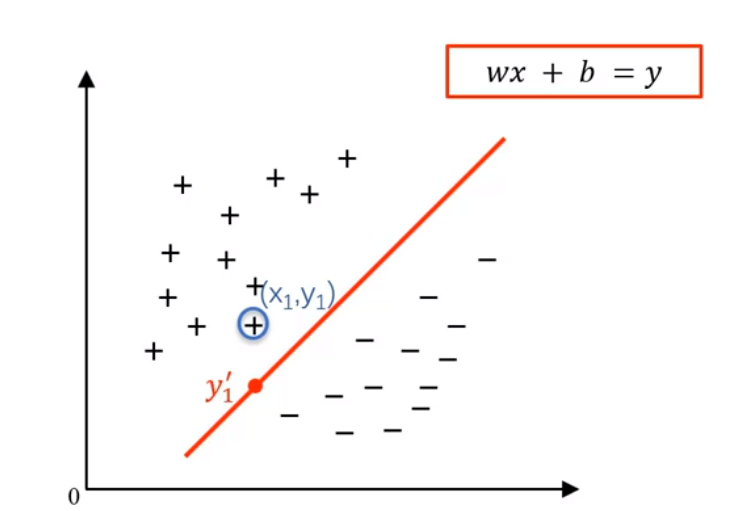
分类器应选择”正中间”,容忍性好,鲁棒性高,泛化能力最强
1、SVM最优化问题的数学推导
点到线的距离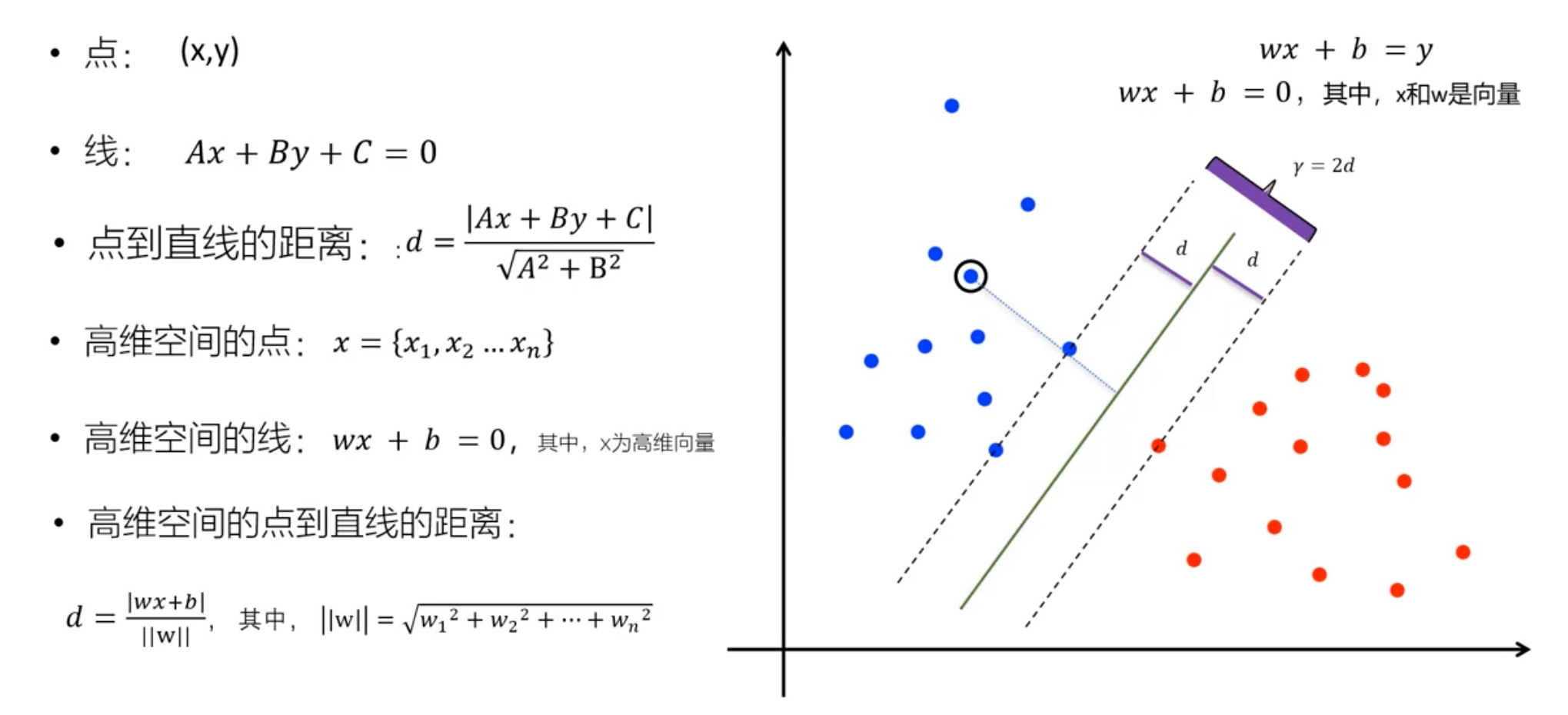
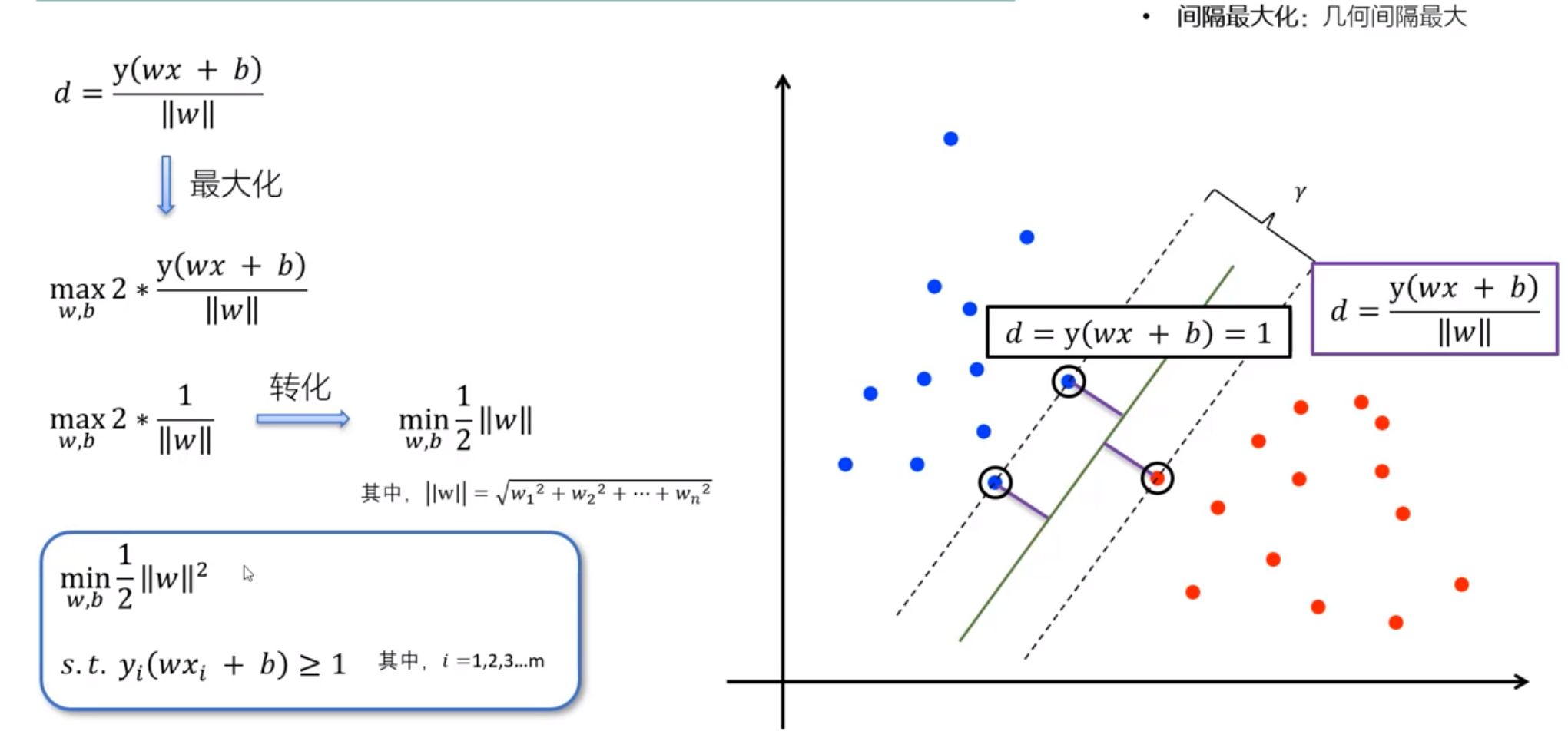
s.t. = subject to
2、拉格朗日乘数法
有约束优化问题的集合意象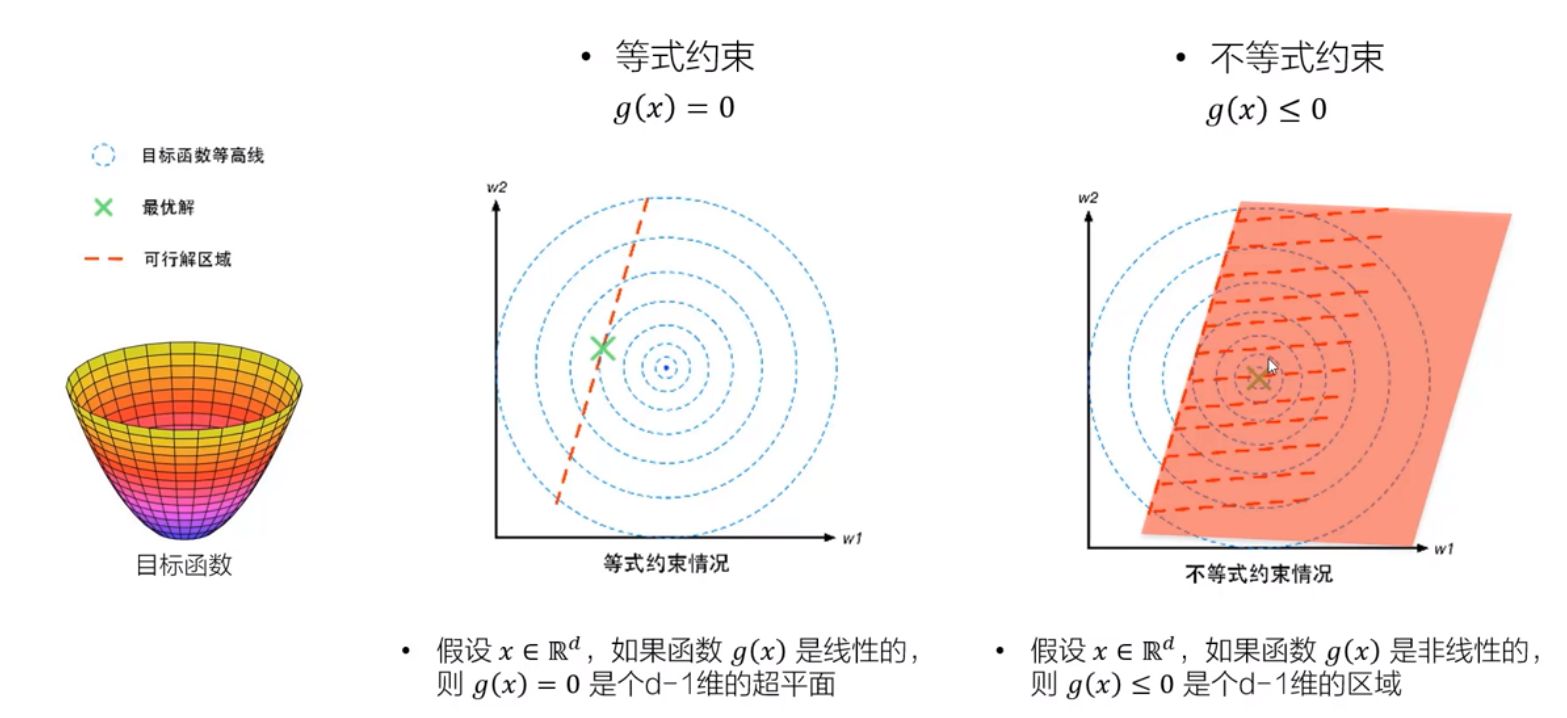

3、凸优化问题
凸集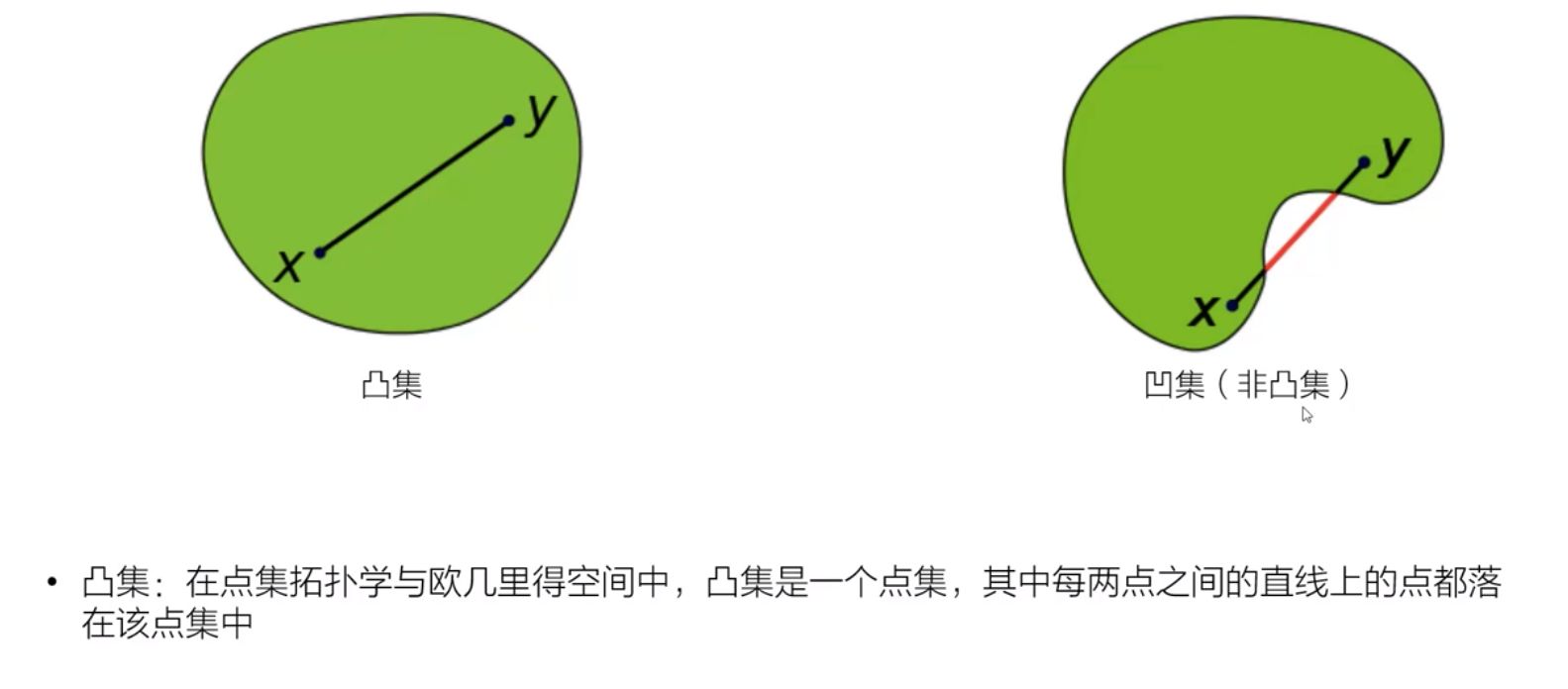
- 凸函数同时满足以下条件
- 函数的定义域是向量空间$R^n$上的凸集- 定义域内有任意两点$x_1$,$x_2$,并且,存在$\theta\in(0,1)$,得:
$f({\theta}x_1+(1-{\theta})x_2)≤{\theta}f(x_1)+(1-{\theta})f(x_2)$那么函数 $f(x)$ 为凸函数
- 定义域内有任意两点$x_1$,$x_2$,并且,存在$\theta\in(0,1)$,得:
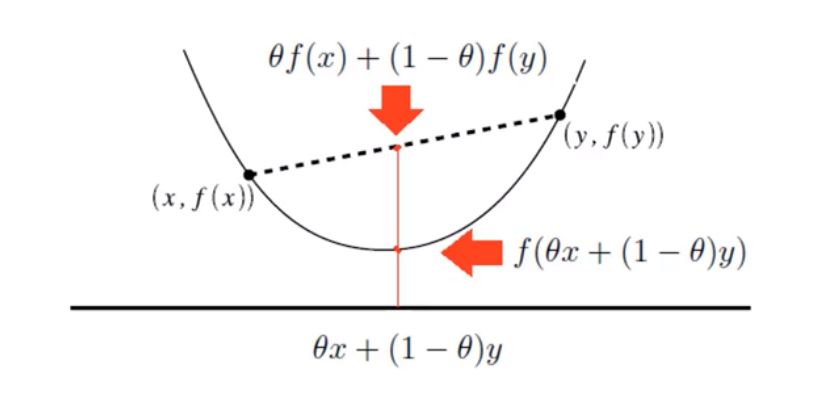
弦一定在函数曲线的上方
凸优化:凸优化是指一种比较特殊的优化,是指求取最小值的目标函数为凸函数的一类优化问
题。其中目标函数为凸函数且定义域为凸集的优化问题称为无约束凸优化问题。
目标函数和不等式约束函数均为凸函数,等式约束函数为仿射函数,并且定义域为凸集的 优化问题为约束优化问题。
凸优化性质:
1、目的是求取目标函数的最小值;
2、目标函数和不等式约束函数都是凸函数,定义域是凸集;
3、若存在等式约束函数,则等式约束函数为仿射函数;
4、对于凸优化问题具有良好的性质,局部最优解便是全局最优解。
$\underset {x}{min} f(x)$
$s.t. h_i(x)=0 (i=1,..,m),$
$ g_j(x)≤0(j=1,..,n) .$
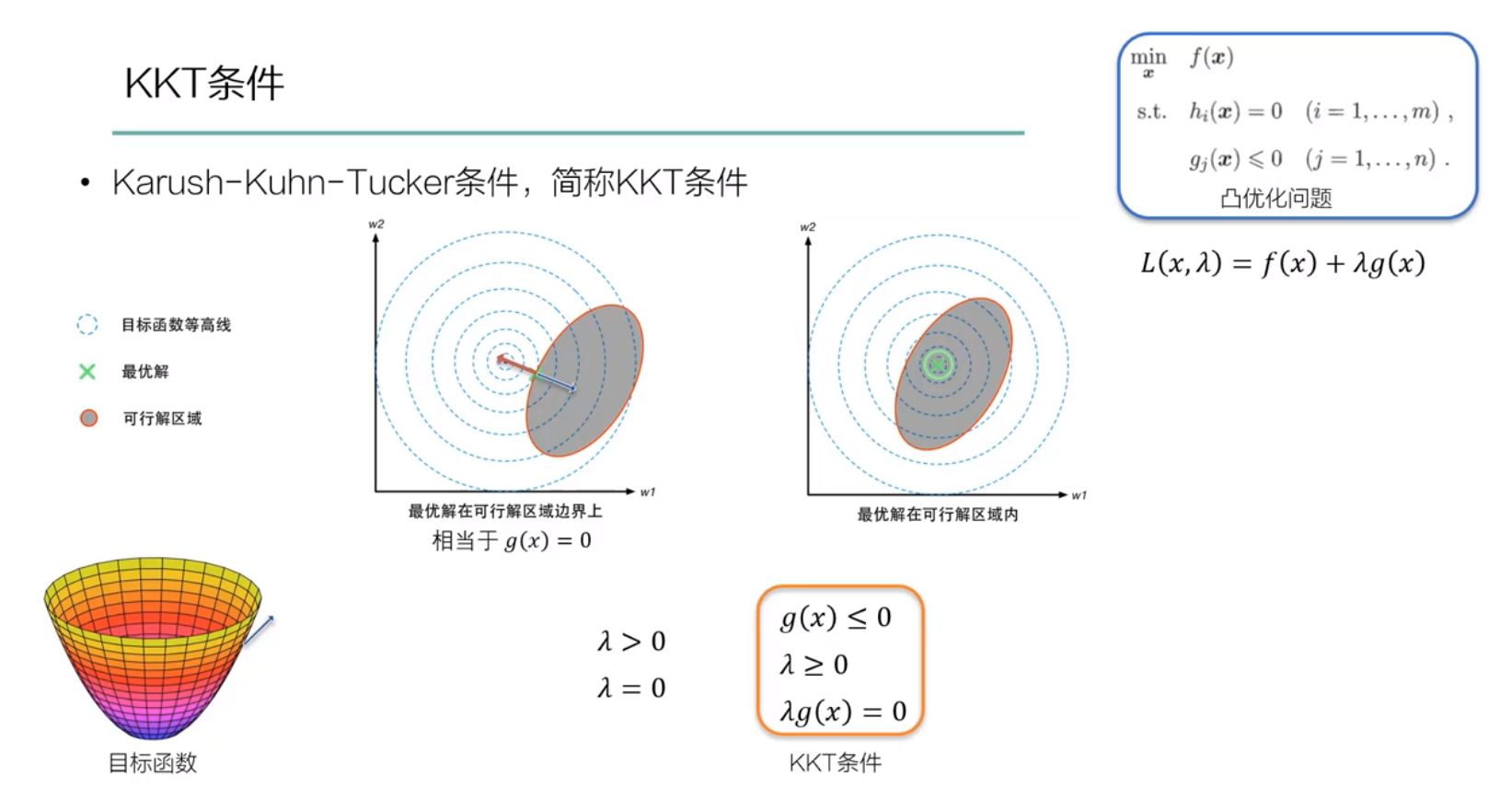
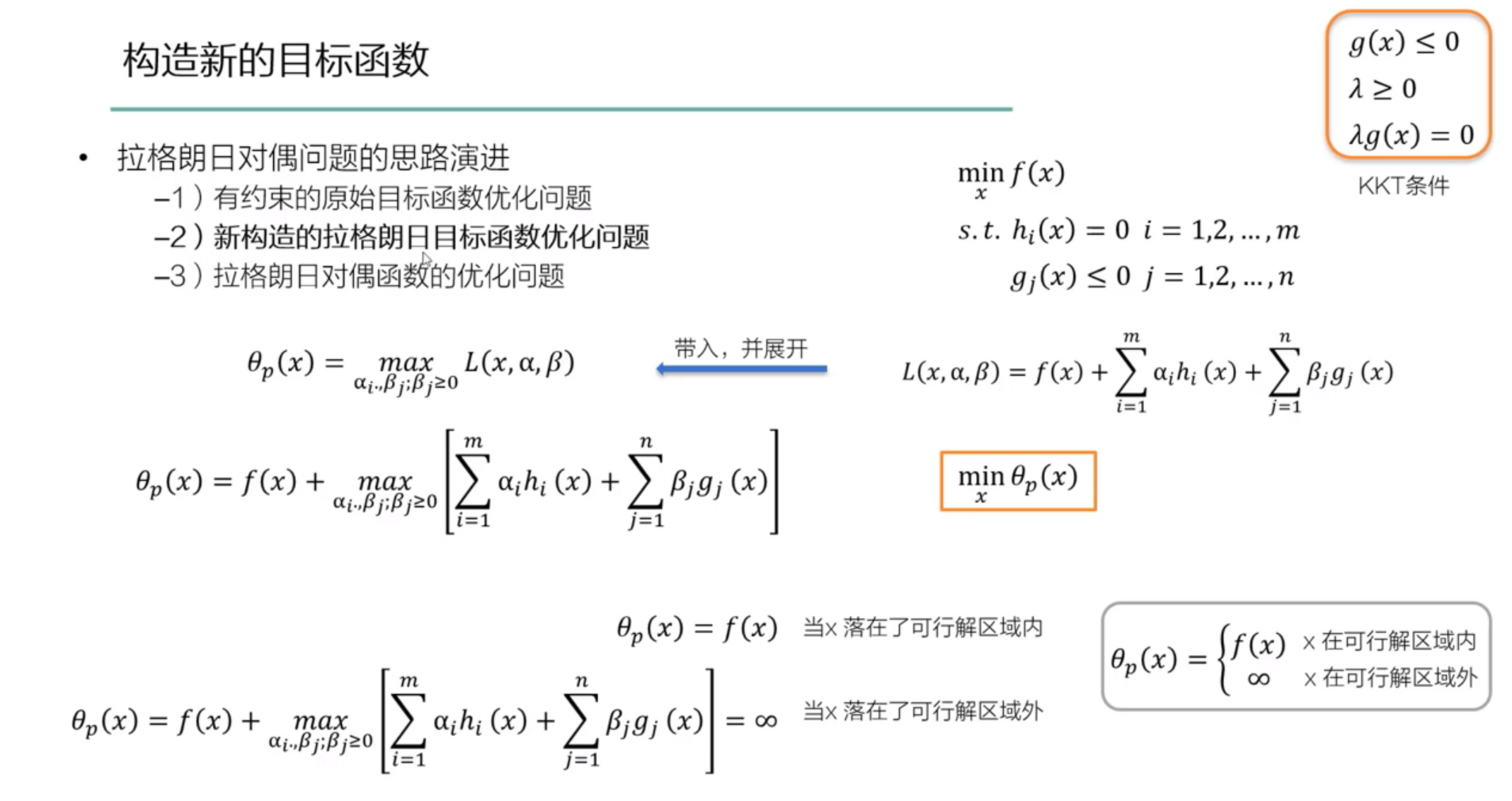
4、拉格朗日对偶问题
- 拉格朗日对偶问题的思路演进
- 有约束的原始目标函数优化问题
- 新构造的拉格朗日目标函数优化问题
- 拉格朗日对偶函数的优化问题
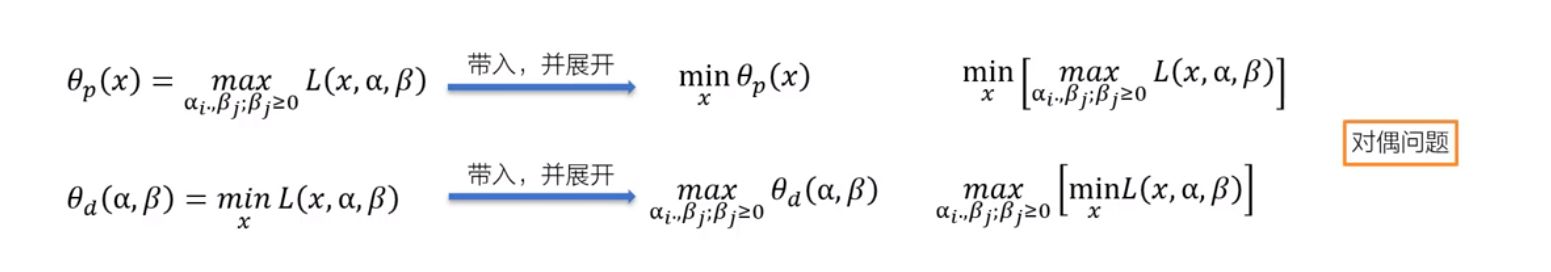
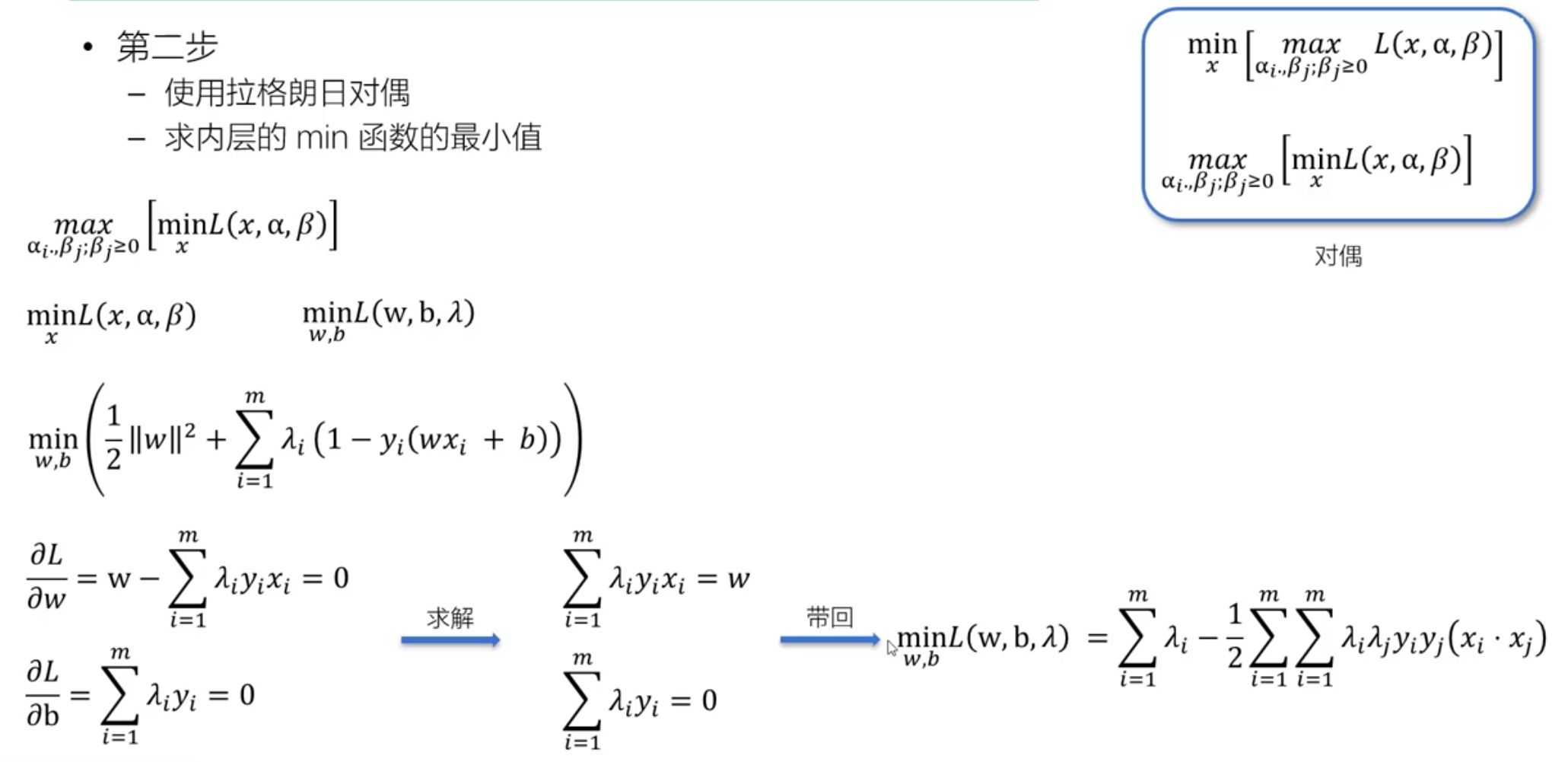
二、SVM最优化问题的计算

- 求阶SVM总共分为五步:
- 1)构造拉格朗日函数
- 2)构造拉格朗日对偶3)使用SMO算法
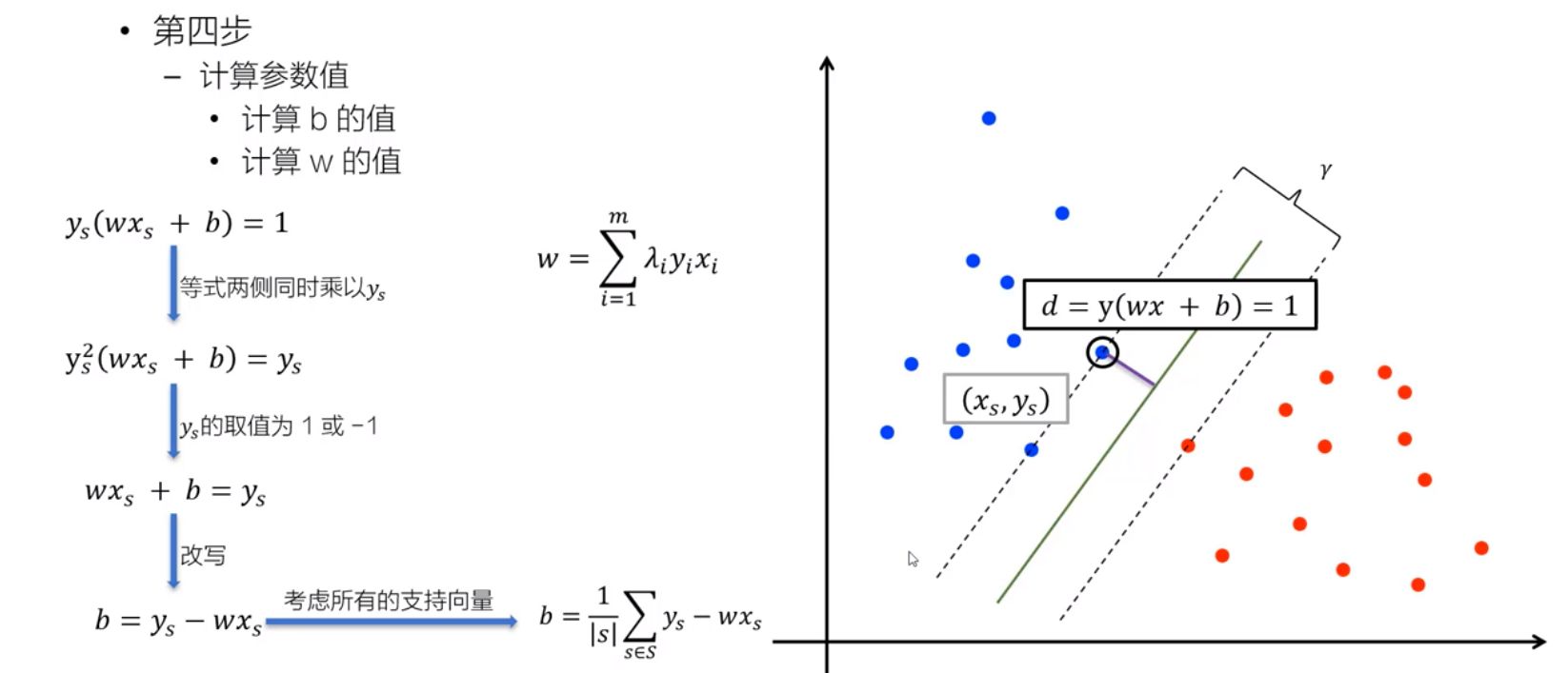
- 4)计算参数值
- 5)预测


- SMO(Sequential Minimal Optimization)算法
-序列最小优化算法 - 核心思想
- 先固定住所有参数,然后放开一个参数
- 每次只优化这一个参数
- 仅求当前这个优化参数的极值


三、软间隔,核函数,SVM优缺点分析
1、软间隔
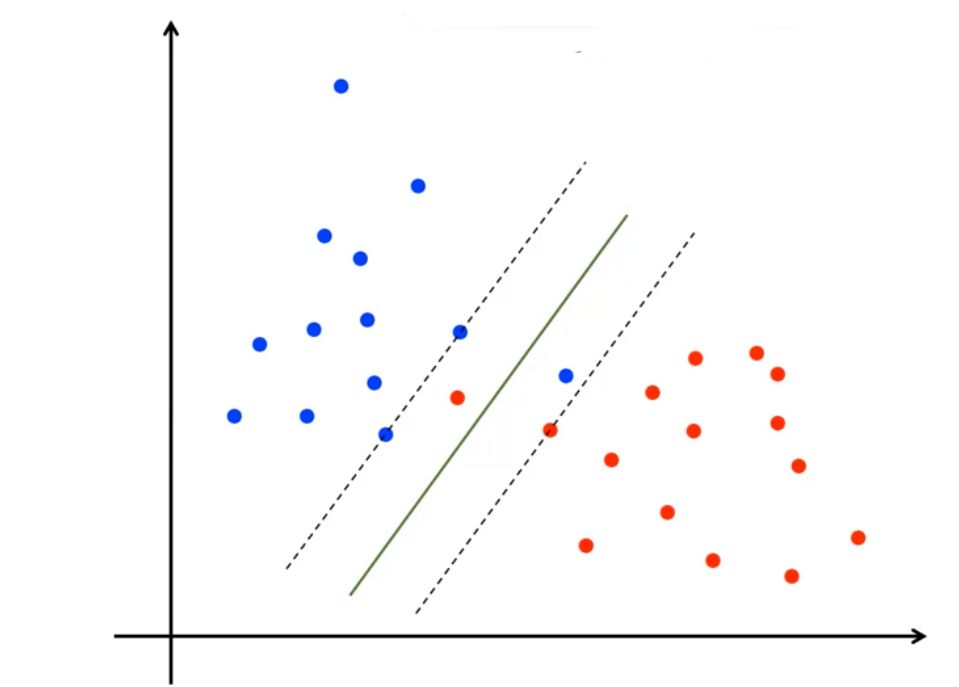
现实任务中很难使得训练样本在特征空间中线性可分
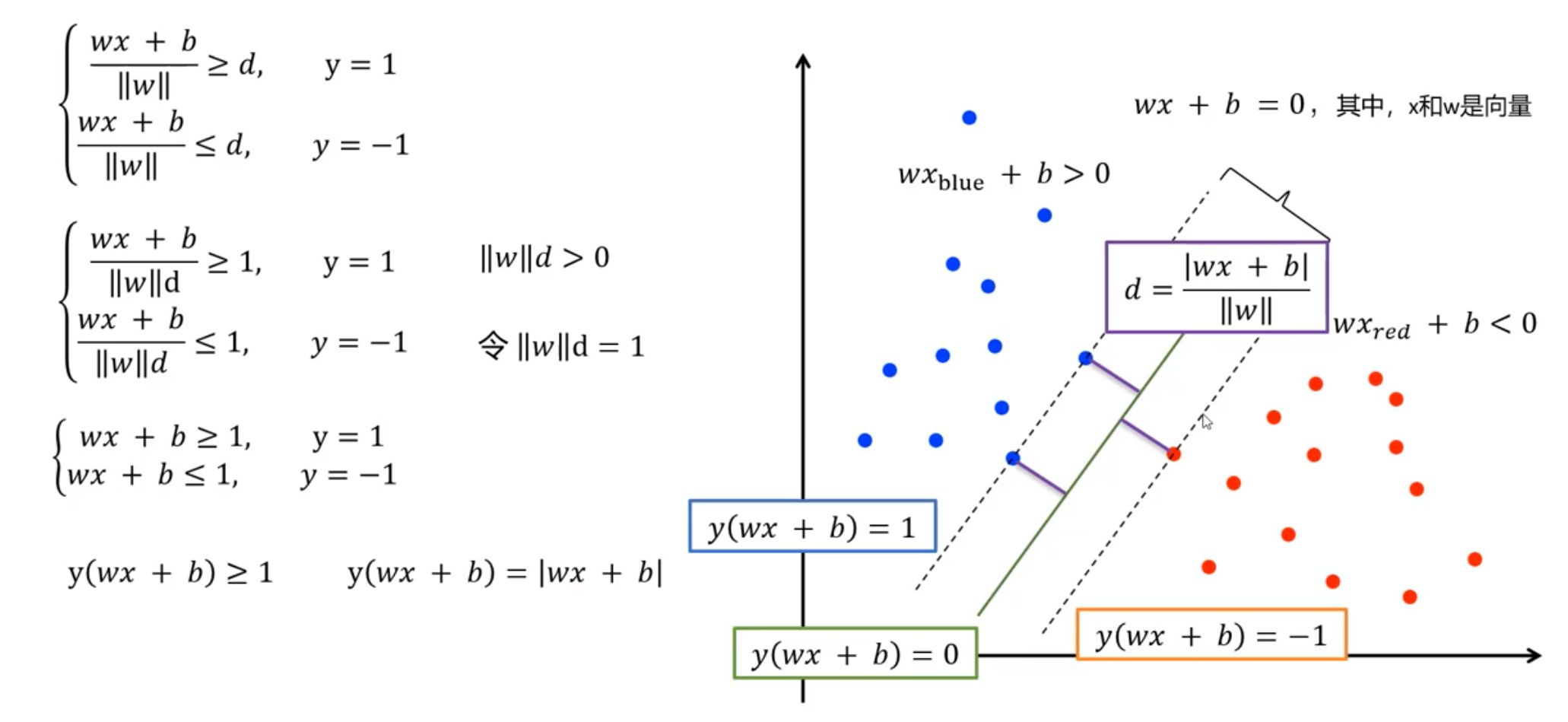
硬间隔约束条件:$y_i(wx_i+b)\geq1$
- 引入“松弛变量”(slack variables) $\xi_{i}\geq0$,允许SVM在一些样本上出错,即允许某些样本不满足约束$y_i(wx_i+b)\geq1$
- 在最大化间隔的同时,不满足约束的样本应尽可能少
$\underset {\omega,b,\xii}{min}\frac{1}{2}||\omega||^2+\lambda\sum\limits{i=0}^{m}\xi_i$$s.t. y_i(w^Tx_i+b)\geq1-\xi_i$ $\xi_i\geq0,i=1,2,...,m$ <font color=red>$\lambda$ 越大,模型对分类错误的容忍度越低</font> <font color=red>$\lambda$ 越小,模型对分类错误的容忍度越高</font>
hinge损失函数:$l_{hinge}(z)=max(0,1-z)$
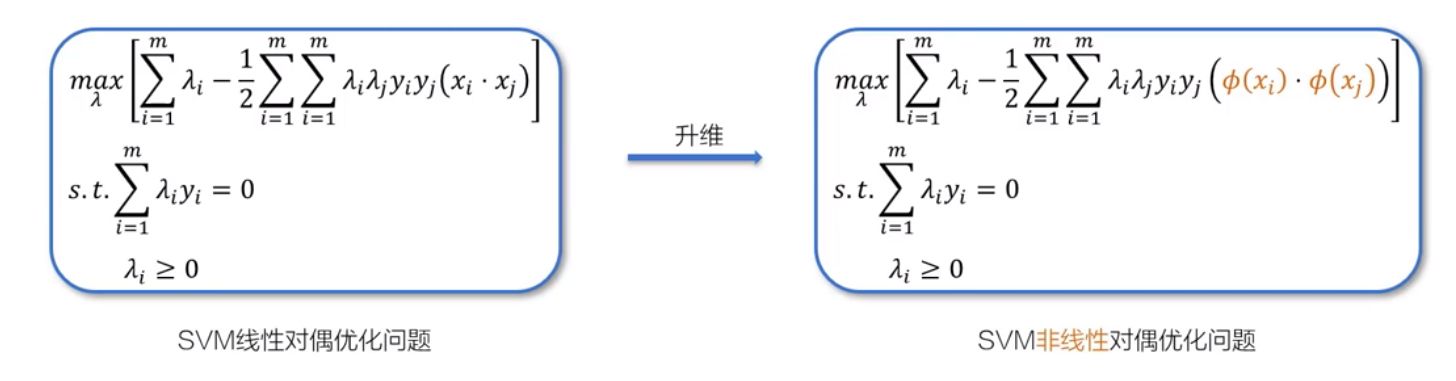
2、核函数
线性不可分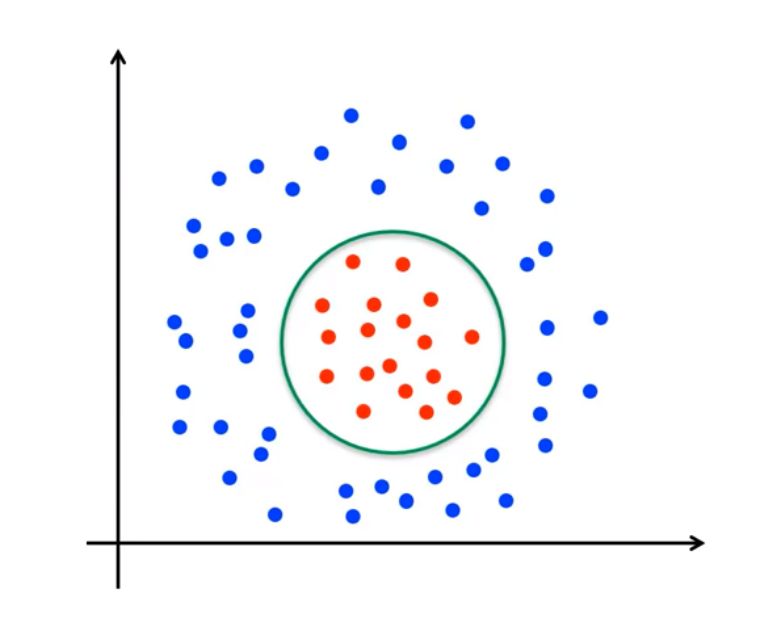
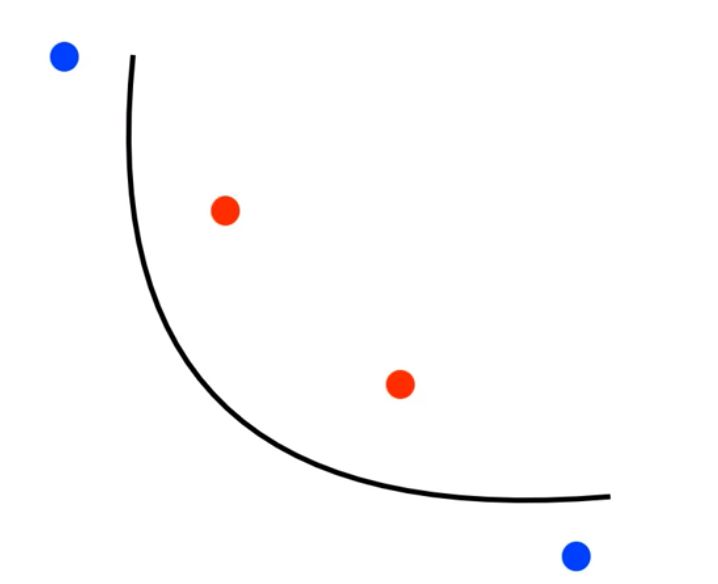
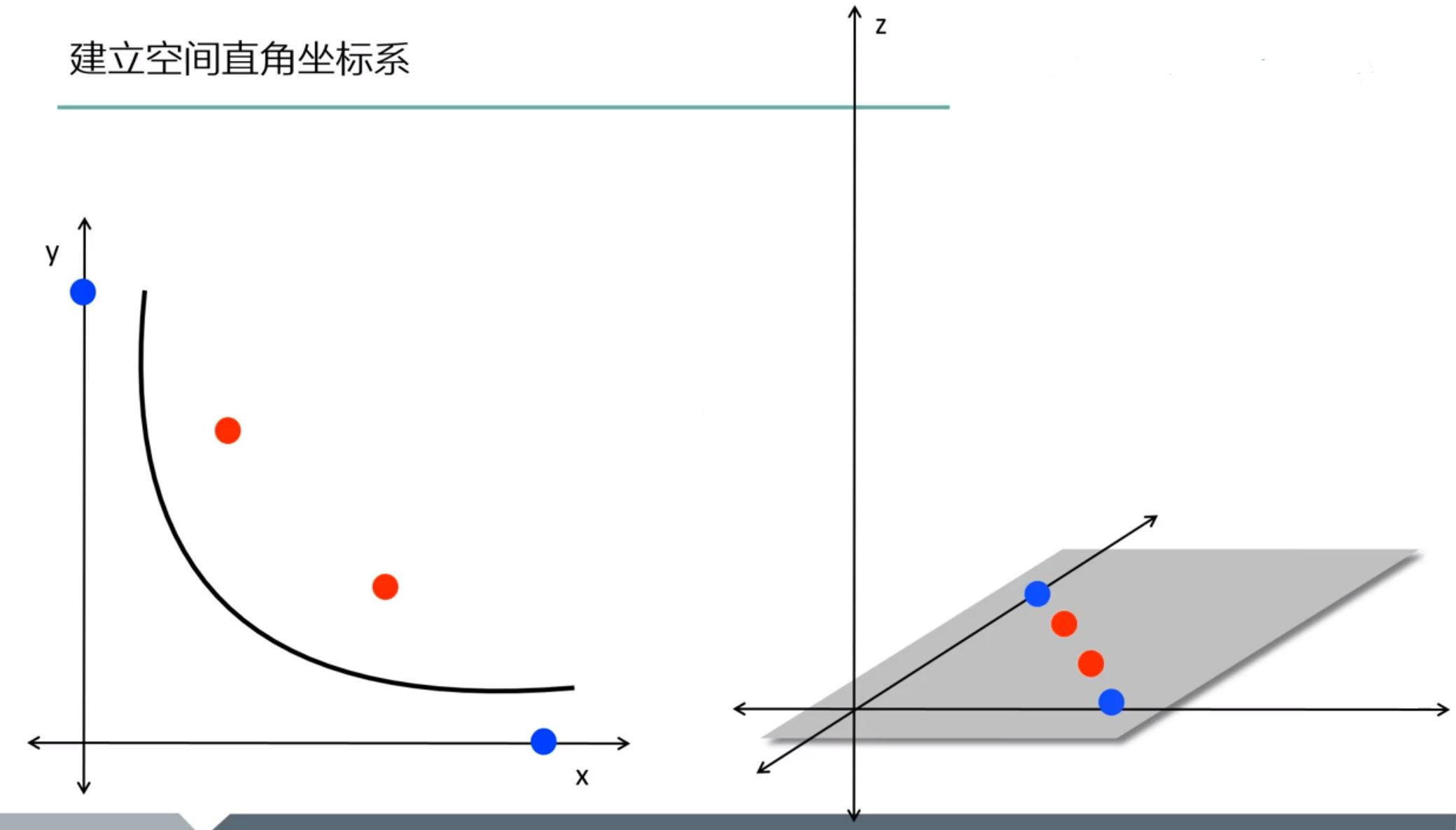
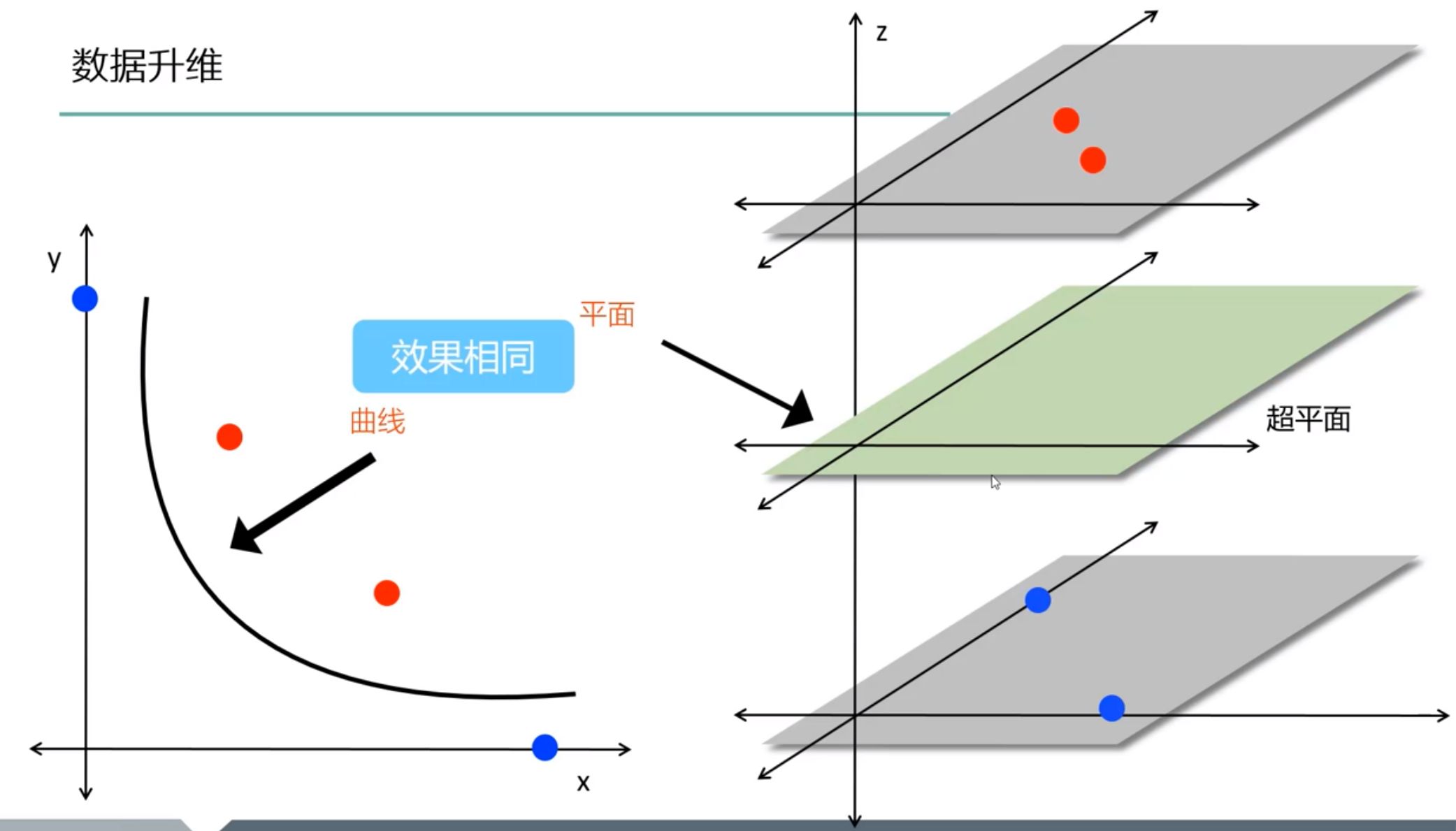
- 通过核函数来升维
- 旧目标函数:$f(x)=wx+b$
- 新目标函数:$f(x)=w\phi(x)+b$