一、聚类算法之k-means
1、什么是聚类
有监督学习
回归
线性回归
岭回归
分类
- 朴素贝叶斯 - svm
- 无监督学习
- 聚类
- k-means
- 降维
- PCA降维
2、k-means算法运算步骤
- 假定我们要对N个样本观测做聚类,要求聚为K类:
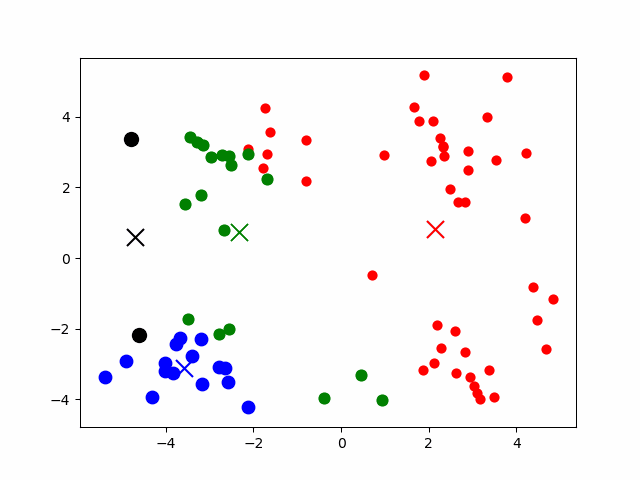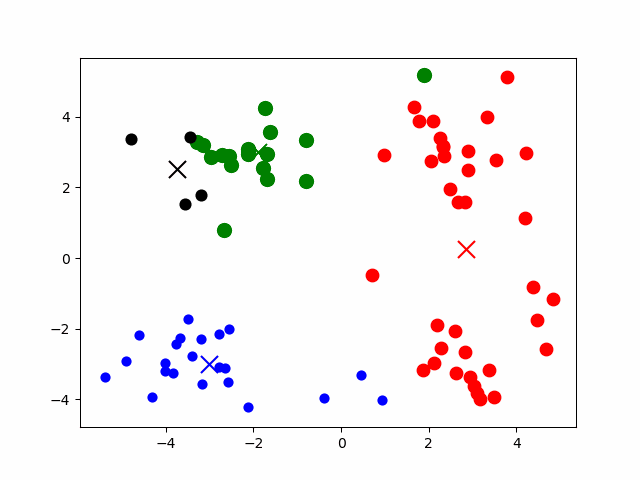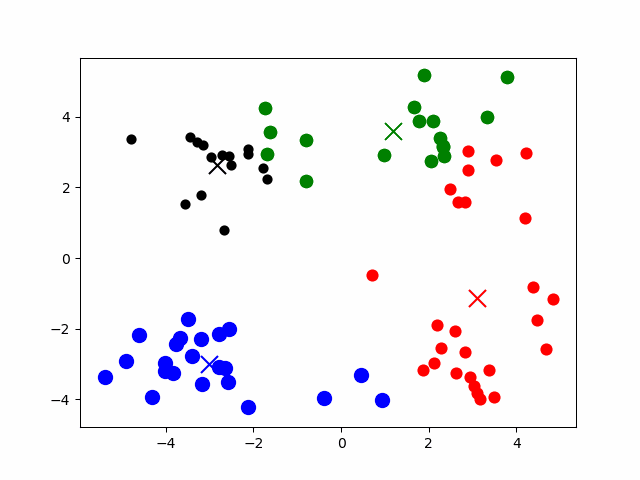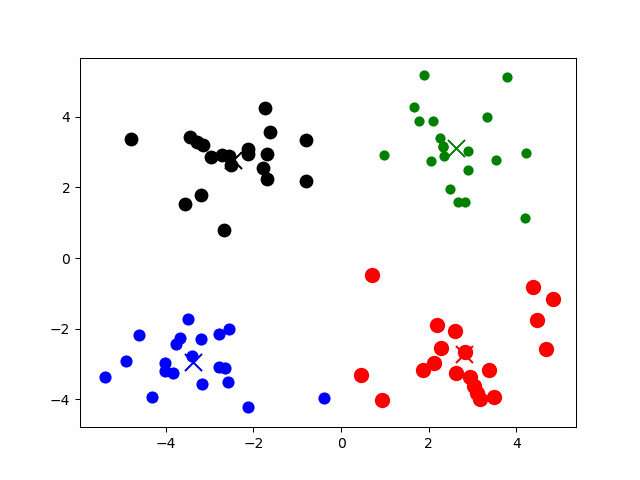
1、初始化:选择K个点作为初始中心点
2、计算所有样本到所有中心点的距离(中心点的数量为k)
3、把样本归为距离中心点最近的类别(共k个类别)
4、计算每个类别内的样本均值
该均值作为新的中心点
5、重复第2-4步,直到结束。
结束条件:中心点不再改变或达到指定的迭代次数
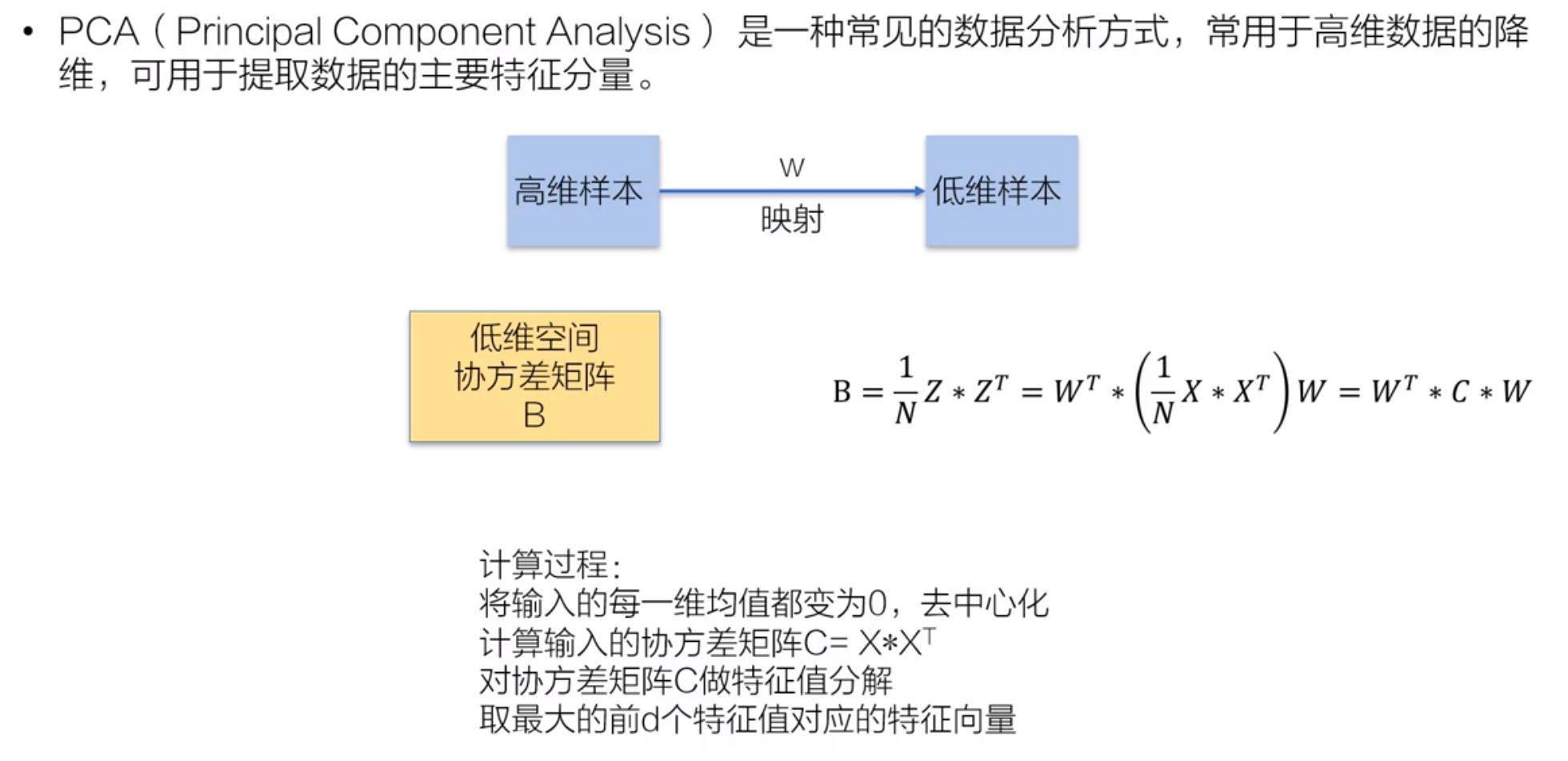
欧氏距离
高维向量:
-A={$a_1,a_2,a_3,…a_n$}
-B={$b_1,b_2,b_3,…b_n$}
$D=\sqrt{(a_1-b_1)^2+(a_2-b_2)^2+…+(a_n-b_n)^2}$每个数据分配给距离最近的类
-$arg\underset {j}{min}||x_n-C_j||^2$
-其中,$C_j$为聚类中心点
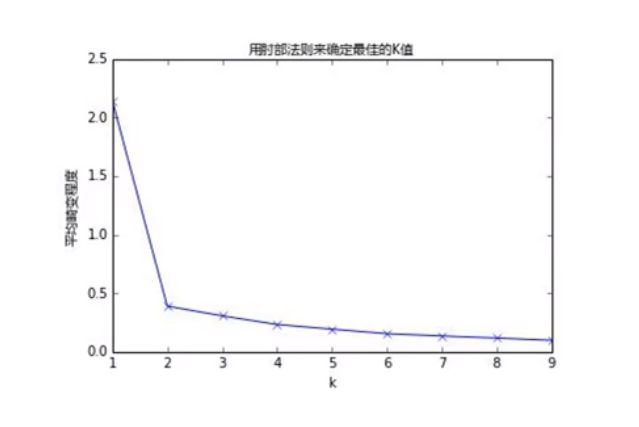
3、k-means算法效果的度量

K设置得越大,样本划分得就越细,每个簇的聚合程度就越高,误差平方和SSE自然就越小
手肘法
二、降维
1、为什么降维
- 高维的存在的问题:
- 数据维数高
- 算法适配困难
- 计算速度慢
- 模型效果差
- 降维的作用:
通过获得一组基本上是重要特征的主变量来减少所考虑的特征变量的过程 - 降维的好处:
- 数据需要的存储空间减少
- 低维数据有助于减少训练时长
- 一些算法在高维度数据上容易表现不佳
- 降维可以用删除冗余特征解决多重共线性问题
- 降维有助于数据可视化
2、降维的角度
- 特征抽取
- 维度空间变换
- 高维空间到低维空间的投影
- 对高维的样本空间进行一种低纬度的描述
- 常用降维方法
- 主成分分析PCA
- 多维缩放(MDS)
- 等度量映射(Isomap)
- 局部线性嵌入(LLE)
PCA算法